Python Notes¶
Base¶
xrange vs range
基本都在循环时使用,输出结果也是一样的,但略有差异
- range 直接生成一个 list 对象
- xrange 返回一个生成器。性能会比 range 好,特别是很大的时候。
-m: run modules as scripts
python -m lets you run modules as scripts, and it reflects the motto–“batteries included”. Here are some powerful features/functions, such as creating a simple http server
python3 -m http.server 80
python -m SimpleHTTPServer 80
-u¶
For the following scripts,
import time
def slow_function():
for i in range(100):
time.sleep(1)
print(f"iter {i}: para = ...")
slow_function()
The output file for
python main.py > output.txt &
is only created after the program finished. For a real-time version, add -u option, i.e.,
python -u main.py > output.txt &
refer to
Python: significance of -u option?
It seems related to sys.stdout.flush().
A data buffer is a region of physical memory storage used to temporarily store data while it is being moved from one place to another. The data is stored in a buffer as it is retrieved from an input device or just before it is sent to an output device or when moving data between processes within a computer. Python’s standard out is buffered. This means that it collects some data before it is written to standard out and when the buffer gets filled, then it is written on the terminal or any other output stream.
import sys
import time
for i in range(3):
print(i)
time.sleep(i)
import sys
import time
for i in range(3):
print(i, end=' ')
time.sleep(i)
import sys
import time
for i in range(3):
print(i, end=' ')
sys.stdout.flush()
## equivalent to
#print(i, end=' ', flush=True)
time.sleep(i)
with statement¶
参考
简言之,“使用with后不管with中的代码出现什么错误,都会进行对当前对象进行清理工作。”
这也就是为什么在用 MySQLdb 的时候,称“With the with keyword, the Python interpreter automatically releases the resources. It also provides error handling.” 详见MySQL Python tutorial - programming MySQL in Python
另外,现在经常在神经网络中碰到,如
import tensorflow as tf
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x**2
dy_dx = tape.gradient(y, x)
usage of yield¶
We should use yield when we want to iterate over a sequence, but don’t want to store the entire sequence in memory.
More details refer to When to use yield instead of return in Python?
An example gave in Squaring all elements in a list
>>> def square(list):
... for i in list:
... yield i ** 2
...
>>> square([1,2])
<generator object square at 0x7f343963dca8>
>>> for i in square([1,2]):
... print(i)
...
1
4
along with other methods to square a list,
>>> list = [1, 2]
>>> [i**2 for i in list]
[1, 4]
>>> map(lambda x: x**2, list)
<map object at 0x7f3439642f60>
>>> for i in map(lambda x: x**2, list):
... print(i)
...
1
4
>>> ret = []
>>> for i in list:
... ret.append(i**2)
...
>>> ret
[1, 4]
Class¶
新式类 vs 经典类 (class ClassName vs class ClassName(object))
- python 2.x 中,默认为经典类,只有当写成
class A(object)才成为新式类 - python 3.x 中,默认为新式类
- In python 2.x, when you inherit from “object” you class is a “new style” class; the non inheriting from “object” case creates an “old style” class.
- In python 3.x, all classes are new style - no need to set the metaclass.
__getitem__ and __setitem__
I came across the usage of __getitem__ here, which seems powerful, and not only accept
T[x, y]
also supports
T[[x, y]]
in my code, where T is an instance of a class and [x, y] is the coordinate. The [] is enabled due to the __getitem__ method.
class TildCoder():
def __init(...):
...
def __getitem__(self, x):
...
Then I found more detailed explanation for the usage.
The
[]syntax for getting item by key or index is just syntax sugar. When you evaluatea[i], Python callsa.__getitem__(i)ortype(a).__getitem__(a, i).
@staticmethod vs @classmethod
参考
CLI Options¶
sys.argv
The arguments are stored in the array sys.argv, where the first element is the script name itself.
import sys
from glob import glob
if __name__ == '__main__':
print(sys.argv)
With quote, the character * would expanding before passing into the argument.
$ python star_arg.py ../*.png
['star_arg.py', '../error_jupyter_1.png', '../error_jupyter.png', '../err_theano.png', '../ipython.png', '../spyder-qtconsole.png']
$ python star_arg.py "../*.png"
['star_arg.py', '../*.png']
If we want to wrap it with a bash function,
$ star_arg() { python star_arg.py $1 ; }
The quote for the pattern containing * is also necessary, otherwise it first expands and just passes the first matched filename due to $1,
$ star_arg ../*.png
['star_arg.py', '../error_jupyter_1.png']
$ star_arg "../*.png"
['star_arg.py', '../error_jupyter_1.png', '../error_jupyter.png', '../err_theano.png', '../ipython.png', '../spyder-qtconsole.png']
But note that the above bash function does not wrap $1. With quote, the original string can be passed into python script
$ star_arg2() { python star_arg.py "$1" ; }
$ star_arg2 "../*.png"
['star_arg.py', '../*.png']
$ star_arg2 ../*.png
['star_arg.py', '../error_jupyter_1.png']
argparse
Documentation: argparse — Parser for command-line options, arguments and sub-commands
An example: jieba/main.py
click
Info
More related code can be found in My Code Results on GitHub
It enables to use command line arguments. For example,
import click # DO NOT NAME THE FILE AS THE SAME NAME
@click.command()
@click.option("--a", default = 1)
@click.option("--b", is_flag = True, default = False)
@click.option("--c", default = 2, type = float)
def main(a, b, c):
print(f"a = {a}, b = {b}, c = {c}")
if __name__ == '__main__':
main()
$ python3 ex_click.py --a 1 --b
a = 1, b = True
$ python3 ex_click.py --a 1
a = 1, b = False
$ python3 ex_click.py --a 2
a = 2, b = False
Warning
The script filename cannot be the same as the module name, click.py. Otherwise, it throws,
$ python3 click.py --a 1 --b
Traceback (most recent call last):
File "click.py", line 1, in <module>
import click
File "/media/weiya/Seagate/GitHub/techNotes/docs/python/ex/click.py", line 3, in <module>
@click.command()
AttributeError: module 'click' has no attribute 'command'
float value
With
@click.option("--c", default = 2)
$ python ex_click.py --a 1 --b --c 2.0
Usage: ex_click.py [OPTIONS]
Try 'ex_click.py --help' for help.
Error: Invalid value for '--c': 2.0 is not a valid integer
type = float needs to be specified.
FileIO¶
read two files simultaneously¶
with open("file1.txt") as f1, open("file2.txt) as f2:
for l1, l2 in zip(f1, f2):
l1.strip() # rm `\n`
l2.strip()
refer to Reading two text files line by line simultaneously - Stack Overflow
Info
写入 non-ascii 字符¶
f = open("filename", "w")
write_str = u'''
some non ascii symbols
'''
f.write(write.str)
会报错
'ascii' codec can't encode character
参考 Python: write a list with non-ASCII characters to a text file 采用 codecs.open(, "w", encoding="utf-8") 可以解决需求。
URL string to normal string¶
参考transform-url-string-into-normal-string-in-python-20-to-space-etc
- python2
import urllib2
print urllib2.unquote("%CE%B1%CE%BB%20")
- python3
from urllib.parse import unquote
print(unquote("%CE%B1%CE%BB%20"))
<U5¶
I met this term in How to convert numpy object array into str/unicode array?
I am confused about the official english documentation
A Chinese answer solves my question,
<表示字节顺序,小端(最小有效字节存储在最小地址中)U表示Unicode,数据类型5表示元素位长,数据大小
u/U, r/R, b in string¶
-
u/U: 表示unicode字符串。不是仅仅是针对中文, 可以针对任何的字符串,代表是对字符串进行unicode编码。一般英文字符在使用各种编码下, 基本都可以正常解析, 所以一般不带u;但是中文, 必须表明所需编码, 否则一旦编码转换就会出现乱码。建议所有编码方式采用utf8
-
r/R: 非转义的原始字符串,常用于正则表达式 re 中。
-
b:bytes:
- python3.x里默认的str是(py2.x里的)unicode, bytes是(py2.x)的str, b”“前缀代表的就是bytes
- python2.x里, b前缀没什么具体意义, 只是为了兼容python3.x的这种写法
另外
str->bytes: encodebytes->str: decode
# python 3.6: str 为 Unicode
>>> "中文".encode("utf8")
b'\xe4\xb8\xad\xe6\x96\x87'
>>> "中文".encode("utf8").decode("utf8")
'中文'
# python 2.7: str 为 bytes
>>> "中文"
'\xe4\xb8\xad\xe6\x96\x87'
>>> "中文".decode("utf8")
u'\u4e2d\u6587'
>>> print("中文".decode("utf8"))
中文
参考:
Function¶
*args and **args¶
*args: pass a non-keyword and variable-length argument list to a function.**args: pass a keyworded, variable-length argument list, actuallydict
refer to *args and **kwargs in Python, and Asterisks in Python: what they are and how to use them
One example,
def feature_size(self):
return self.conv3(self.conv2(self.conv1(torch.zeros(1, *self.input_shape)))).view(1, -1).size(1)
where *self.input_shape aims to unpacking something like [3, 4, 5] to 3, 4, 5.
annotations¶
When I am writing the custom loss function in XGBoost, there are some new syntax in the example function,
def squared_log(predt: np.ndarray,
dtrain: xgb.DMatrix) -> Tuple[np.ndarray, np.ndarray]:
what is the meaning of : and ->. Then I found that they are functional annotations.
By itself, Python does not attach any particular meaning or significance to annotations.
The only way that annotations take on meaning is when they are interpreted by third-party libraries.
No Tuple here¶
Actually, seems no need to add Tuple before [np.ndarray, np.ndarray], which will throws an error
NameError: name ‘Tuple’ is not defined
Ohhh, to avoid such problem,
from typing import Tuple, Dict, List
refer to custom_rmsle.py#L16
IPython¶
Built-in magic commands¶
Refer to  for more details.
for more details.
%matplotlib inlineenables the inline backend for usage with the IPython notebook.!lssimply calls system’sls, but!!lsalso returns the result formatted as a list, which is equivalent to%sx ls.%sx: shell execute, run shell command and capture output, and!!is short-hand.
remote ipython kernel¶
一直想玩 jupyter 的远程 ipython kernel 连接,这样可以减轻本机的压力。
这两篇介绍得很详细,但是最后设置 ssh 那一步总是报错,总是说无法连接。
- Connecting Spyder IDE to a remote IPython kernel
- How to connect your Spyder IDE to an external ipython kernel with SSH PuTTY tunnel
因为我是直接把 id_rsa.pub 文件当作 .pem 文件,但如果我换成密码登录后就成功了。
而如果直接命令行操作,则就像正常 ssh 一样,也会成功。
所以中间的差异应该就是 .pem 与 id_rsa.pub 不等同。具体比较详见 what is the difference between various keys in public key encryption
JSON¶
json.loads: convert string to json
payload='{'name': weiya}'
# payload='payload = {'name': weiya}'
换成json
json.loads(payload)
注意不能采用注释掉的部分。
dumps vs dump
简言之,dumps()和loads()都是针对字符串而言的,而dump()和load()是针对文件而言的。具体细节参见python json.dumps() json.dump()的区别 - wswang - 博客园
Jupyter¶
GitHub 语言比例过分倾斜¶
LInguist is reporting my project as a Jupyter Notebook
jupyter notebook 出错¶

可以通过
rm -r .pki
创建 jupyter notebook 权限问题¶
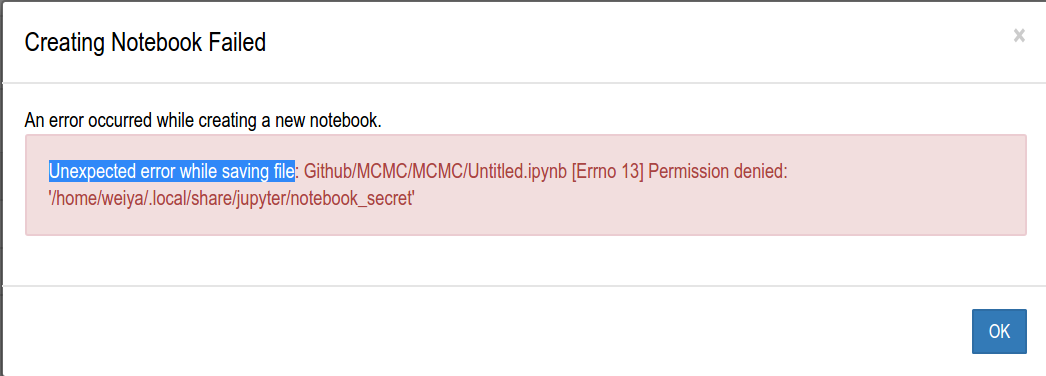
原因是所给的路径的用户权限不一致,jupyter的用户及用户组均为root,为解决这个问题,直接更改用户权限
sudo chown weiya jupyter/ -R
sudo chgrp weiya jupyter/ -R
nbconvert failed: validate() got an unexpected keyword argument 'relax_add_props'¶
refer to nbconvert failed: validate() got an unexpected keyword argument ‘relax_add_props’ #2901
其实我的版本是一致的,但可能由于我进入 Jupyter notebook 方式不一样。
- 一开始,直接从base 进入,然后选择 snakes 的 kernel,导出失败,错误原因如上
- 直接在 snakes 进入 Jupyter notebook,这样可以成功导出
different kernels¶
Python¶
其实不用对每个 environment 安装单独的 jupyter,只要安装 ipykernel 就好,这样都能从 base environment 中通过 jupyter 来选择不同 kernel,详见 Kernels for different environments
$ conda activate myenv
$ conda install ipykernel
$ python -m ipykernel install --user --name myenv --display-name "Python (myenv)"
Julia¶
打开特定版本的 Julia,
> add IJulia
R¶
install.packages('IRkernel')
#IRkernel::installspec()
IRkernel::installspec(name="3.6.0", displayname = "R 3.6.0")
management¶
列出所有安装的 kernel,
$ jupyter kernelspec list
Available kernels:
3.6.0 /home/project09/.local/share/jupyter/kernels/3.6.0
ir /home/project09/.local/share/jupyter/kernels/ir
julia-1.1 /home/project09/.local/share/jupyter/kernels/julia-1.1
julia-1.4 /home/project09/.local/share/jupyter/kernels/julia-1.4
mu-lux-cz /home/project09/.local/share/jupyter/kernels/mu-lux-cz
sam /home/project09/.local/share/jupyter/kernels/sam
python3 /home/project09/miniconda3/share/jupyter/kernels/python3
但是没有显示出 display name,其定义在文件夹下的 kernel.json 文件中(refer to How to Change Jupyter Notebook Kernel Display Name)
$ jupyter kernelspec list | sed -n '2,$p' | awk '{print $2}' | xargs -I {} grep display {}/kernel.json
"display_name": "R 3.6.0",
"display_name": "R",
"display_name": "Julia 1.1.1",
"display_name": "Julia 1.4.2",
"display_name": "py37",
"display_name": "py37 (sam)",
"display_name": "Python 3",
为了打印出对应的 env 名,
$ paste <(jupyter kernelspec list | sed -n '2,$p') <(jupyter kernelspec list | sed -n '2,$p' | awk '{print $2}' | xargs -I {} grep display {}/kernel.json)
3.6.0 /home/project09/.local/share/jupyter/kernels/3.6.0 "display_name": "R 3.6.0",
ir /home/project09/.local/share/jupyter/kernels/ir "display_name": "R",
julia-1.1 /home/project09/.local/share/jupyter/kernels/julia-1.1 "display_name": "Julia 1.1.1",
julia-1.4 /home/project09/.local/share/jupyter/kernels/julia-1.4 "display_name": "Julia 1.4.2",
mu-lux-cz /home/project09/.local/share/jupyter/kernels/mu-lux-cz "display_name": "py37",
sam /home/project09/.local/share/jupyter/kernels/sam "display_name": "py37 (sam)",
python3 /home/project09/miniconda3/share/jupyter/kernels/python3 "display_name": "Python 3",
Question
此处很不优雅地重新复制了一下 jupyter kernelspec list | sed -n '2,$p',在 pipeline 中是否有更直接的方法?
List¶
find index of an item
>>> [1, 1].index(1)
0
>>> [i for i, e in enumerate([1, 2, 1]) if e == 1]
[0, 2]
>>> g = (i for i, e in enumerate([1, 2, 1]) if e == 1)
>>> next(g)
0
>>> next(g)
2
refer to Finding the index of an item given a list containing it in Python
for loop in list: index a list with another list
L = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h']
Idx = [0, 3, 7]
T = [L[i] for i in Idx]
refer to In Python, how do I index a list with another list?
getting indices of true
>>> t = [False, False, False, False, True, True, False, True, False, False, False, False, False, False, False, False]
>>> [i for i, x in enumerate(t) if x]
[4, 5, 7]
TypeError: unhashable type: 'list'¶
convert a nested list to a list¶
Python 3.6.9 (default, Apr 18 2020, 01:56:04)
[GCC 8.4.0] on linux
>>> set([1,2,3,4,[5,6,7],8,9])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> set([1,2,3,4,(5,6,7),8,9])
{1, 2, 3, 4, (5, 6, 7), 8, 9}
hash a nested list¶
>>> hash([1, 2, 3, [4, 5,], 6, 7])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> hash(tuple([1, 2, 3, [4, 5,], 6, 7]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> hash(tuple([1, 2, 3, tuple([4, 5,]), 6, 7]))
-7943504827826258506
>>> hash([1, 2, 3, tuple([4, 5,]), 6, 7])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
refer to Python: TypeError: unhashable type: ‘list’
convert list of lists to list¶
>>> a = [[1, 2], [3, 4]]
>>> [y for x in a for y in x]
[1, 2, 3, 4]
refer to How to make a flat list out of a list of lists?
matplotlib.pyplot¶
plt.show()is necessary when plotting in the REPL.
seaborn¶
Homepage: seaborn: statistical data visualization
Seaborn的底层是基于Matplotlib的,他们的差异有点像在点餐时选套餐还是自己点的区别,Matplotlib是独立点菜,可能费时费心(尤其是对我这种选择困难症患者…)但最后上桌的菜全是特别适合自己的;而Seaborn是点套餐,特别简单,一切都是配好的,虽然省时省心,但可能套餐里总有些菜是不那么合自己口味的。
order of xy¶
imshow 中的 origin and extent
Generally, for an array of shape (M, N), the first index runs along the vertical, the second index runs along the horizontal. The pixel centers are at integer positions ranging from 0 to N’ = N - 1 horizontally and from 0 to M’ = M - 1 vertically.
origindetermines how to the data is filled in the bounding box.
an illustrative example,
import matplotlib.pyplot as plt
import matplotlib.cbook as cbook
imgf = cbook.get_sample_data("ada.png")
img = plt.imread(imgf)
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2,2)
ax1.imshow(img, origin = "upper")
ax2.imshow(img, origin = "lower")
# img.shape (803, 512, 4), then transpose
# he first two axes from (0, 1, 2) to (1, 0, 2)
ax3.imshow(img.transpose(1, 0, 2), origin="upper")
ax4.imshow(img.transpose(1, 0, 2), origin="lower")

which is adapted from matplotlib: coordinates convention of image imshow incompatible with plot
tight_layout: subplots 的间距
plt.tight_layout() 可以调节间距,如果有必要,可以带上参数,比如,B spline in R, C++ and Python
plt.tight_layout(pad = 3.0)
set_aspect: equal axis aspect ratio
According to the official documentation,
fig, ax = plt.subplots(1, 3)
ax[0].plot(3*np.cos(an), 3*np.sin(an))
ax[1].plot(3*np.cos(an), 3*np.sin(an))
ax[1].axis("equal")
ax[2].plot(3*np.cos(an), 3*np.sin(an))
ax[2].set_aspect("equal", "box")

we prefer to the last one. If we want to directly call plt instead of fig, ax, then
plt.plot(3*np.cos(an), 3*np.sin(an))
plt.gca().set_aspect("equal", "box")
note the middle gca().
scatter size¶
the size is defined by the area, pyplot scatter plot marker size
interactive mode¶
Info
Related projects: - pause for stopping and resuming to plot - plot every X seconds
math symbols¶
plt.xlabel(r"\lambda")
refer to Writing mathematical expressions
NumPy¶
(R, 1) vs (R, )
The best way to think about NumPy arrays is that they consist of two parts, a data buffer which is just a block of raw elements, and a view which describes how to interpret the data buffer.
>>> np.shape(np.ones((3, 1)))
(3, 1)
>>> np.shape(np.ones((3, )))
(3,)
>>> np.shape(np.ones((3)))
(3,)
>>> np.shape(np.ones(3))
(3,)
>>> np.shape(np.ones(3, 1)) # ERROR!
broadcast in division
>>> a = np.sum([[0, 1.0], [0, 5.0]], axis=1)
>>> c = np.sum([[0, 1.0], [0, 5.0]], axis=1, keepdims=True)
>>> a
array([ 1., 5.])
>>> c
array([[ 1.],
[ 5.]])
>>> a/c
array([[ 1. , 5. ],
[ 0.2, 1. ]])
>>> d
array([[ 1, 5],
[ 0, 10]])
>>> d/c
array([[ 1., 5.],
[ 0., 2.]])
>>> d/a
array([[ 1., 1.],
[ 0., 2.]])
different size: nested list vs dtype=object
- nested list
[[1,2,3],[1,2]]
- numpy
numpy.array([[0,1,2,3], [2,3,4]], dtype=object)
refer to How to make a multidimension numpy array with a varying row size?
np.newaxis
add new dimensions to a numpy array .
>>> a = np.ones((2, 3))
>>> np.shape(a[:, :, None])
(2, 3, 1)
>>> np.shape(a[:, :, np.newaxis])
(2, 3, 1)
array of FALSE/TRUE
np.zeros(10, dtype = bool)
Array of Array
In [29]: a
Out[29]:
array([[ 83., 11.],
[316., 19.],
[372., 35.]])
In [30]: np.hstack([a, a])
Out[30]:
array([[ 83., 11., 83., 11.],
[316., 19., 316., 19.],
[372., 35., 372., 35.]])
In [31]: b = np.array([a, a])
In [32]: b[1]
Out[32]:
array([[ 83., 11.],
[316., 19.],
[372., 35.]])
array_repr: print numpy objects without line breaks
import numpy as np
x_str = np.array_repr(x).replace('\n', '')
print(x_str)
r_: merge multiple slices
x = np.empty((15, 2))
x[np.r_[0:5, 10:15],:]
refer to Numpy: An efficient way to merge multiple slices
but it does not allow the iterator to construct the list,
In: [i:i+3 for i in 1:3]
File "<ipython-input-247-8e21d57e8f2d>", line 1
[i:i+3 for i in 1:3]
^
SyntaxError: invalid syntax
In: np.r_[i:i+3 for i in 1:3]
File "<ipython-input-246-02f2b1ded12b>", line 1
np.r_[i:i+3 for i in 1:3]
^
SyntaxError: invalid syntax
As a comparison, Julia seems more flexible,
julia> vcat([i:i+3 for i in 1:3]...)'
1×12 adjoint(::Vector{Int64}) with eltype Int64:
1 2 3 4 2 3 4 5 3 4 5 6
/=: in-place evaluation
According to the builtin manual, help('/='),
An augmented assignment expression like “x += 1” can be rewritten as “x = x + 1” to achieve a similar, but not exactly equal effect. In the augmented version, “x” is only evaluated once. Also, when possible, the actual operation is performed in-place, meaning that rather than creating a new object and assigning that to the target, the old object is modified instead.
So it would be cautious when using it on arrays,
>>> a = np.array([[1, 2, 3], [4, 5, 6]])
>>> a1 = a[0, ]
>>> a1 /= 0.5
>>> a1
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-106-71f04990b2bb> in <module>
1 a = np.array([[1, 2, 3], [4, 5, 6]])
2 a1 = a[0, ]
----> 3 a1 /= 0.5
4 a1
TypeError: ufunc 'true_divide' output (typecode 'd') could not be coerced to provided output parameter (typecode 'l') according to the casting rule ''same_kind''
The above error is due to incompatible type, so it can be avoided by specifying the element type of the array, but the original array also has been updated,
>>> a = np.array([[1, 2, 3], [4, 5, 6]], dtype = float)
>>> a1 = a[0, ]
>>> a1 /= 0.5
>>> a1
array([2., 4., 6.])
>>> a
array([[2., 4., 6.],
[4., 5., 6.]])
In contrast, / would retain the original array.
>>> a = np.array([[1, 2, 3], [4, 5, 6]], dtype = float)
>>> a1 = a[0, ]
>>> a1 = a1 / 0.5
>>> a1
array([2., 4., 6.])
>>> a
array([[1., 2., 3.],
[4., 5., 6.]])
np.isnan(x) vs x is np.nan
Use np.isnan(x)! When x from an array, x is np.nan return False. (WHY???)
>>> import numpy as np
>>> a = np.zeros(3)
>>> a
array([0., 0., 0.])
>>> a[1] = np.nan
>>> a[1] is np.nan
False
>>> np.isnan(a[1])
True
>>> a1 = np.nan
>>> a1 is np.nan
True
>>> type(a)
<class 'numpy.ndarray'>
>>> type(a[1])
<class 'numpy.float64'>
>>> type(a1)
<class 'float'>
See also

pandas¶
- Homepage: https://pandas.pydata.org/docs/
- Cheatsheet
Tip
- “.fillna()” can pass Series (p) to DataFrame (1xp) with the same index
AttributeError: ‘Index’ object has no attribute ‘apply’
>>> a = pd.DataFrame({"x_1": [1,2], "x_2": [3, 4]})
>>> a
x_1 x_2
0 1 3
1 2 4
>>> a.columns.str.split("_")
Index([['x', '1'], ['x', '2']], dtype='object')
>>>
>>> a.columns.str.split("_").apply(lambda x: int(x[1]))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Index' object has no attribute 'apply'
A workaround is
>>> [int(x[1]) for x in a.columns.str.split("_")]
[1, 2]
See also:
Boolean Series key will be reindexed to match DataFrame index
The warning is due to
df[df.A == x][df.B == y]
The correct way is
df[df.A == x & df.B == y]
See also
Also note that here & cannot be replaced by and.
apply function to column names
one way is to use list comprehension,
df.columns = [col[0:6] for col in df.columns]
see also
re¶
extract the starting position¶
Given an error message returns by decode("utf8") on a problematic characters, such as
>>> "编程".encode("utf8")
b'\xe7\xbc\x96\xe7\xa8\x8b'
>>> b"\xe7\xbc".decode("utf8")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-1: unexpected end of data
>>> e = "'utf-8' codec can't decode bytes in position 0-1: invalid continuation byte"
I want to get the starting position. Suppose only one byte is wrong, and since a Chinese character is encoded by 3 bytes, then there are only two possible cases,
xooandoox: positionn-n+1oxo: positionn
>>> re.search("position ([0-9]{1,3})", e).group(1)
'0'
>>> re.search("position ([0-9]{1,3})", e).group(0)
'position 0'
where () is used to group, and group(1) returns the first group, while group(0) returns the whole match.
又拍云的短信平台¶
参考文献
远程连接 mysql¶
首先需要在服务器端,在my.cnf 中注释掉
# bind-address = 127.0.0.1
并且在 mysql 中创建用户并设置权限,如
create user 'test'@'%' identified by 'test123';
grant all privileges on testdb.* to 'test'@'%' with grant option;
参考
- Host ‘xxx.xx.xxx.xxx’ is not allowed to connect to this MySQL server
- How to allow remote connection to mysql
sphinx 相关¶
init¶
thread vs process¶
# -*- coding: utf-8 -*-
# https://foofish.net/thread-and-process.html
import os
# 进程是资源(CPU、内存等)分配的基本单位,它是程序执行时的一个实例。
# 程序运行时系统就会创建一个进程,并为它分配资源,然后把该进程放入进程就绪队列,
# 进程调度器选中它的时候就会为它分配CPU时间,程序开始真正运行。
print("current process: %s start..." % os.getpid())
pid = os.fork()
if pid == 0:
print('child process: %s, parent process: %s' % (os.getpid(), os.getppid()))
else:
print('process %s create child process: %s' % (os.getpid(), pid) )
# fork函数会返回两次结果,因为操作系统会把当前进程的数据复制一遍,
# 然后程序就分两个进程继续运行后面的代码,fork分别在父进程和子进程中返回,
# 在子进程返回的值pid永远是0,在父进程返回的是子进程的进程id。
# 线程是程序执行时的最小单位,它是进程的一个执行流,
# 是CPU调度和分派的基本单位,一个进程可以由很多个线程组成,
# 线程间共享进程的所有资源,每个线程有自己的堆栈和局部变量。
Kite 使用体验¶
Copilot 一直 detect 不出 spyder,只有刚开始装的时候检测到了,但那时候也没有起作用。而 kite 本身一直在 spyder 右下角的状态栏中。
pip¶
pip list: 查看已安装的包pip install -U: upgrade,但注意-U不能插在pip与install中间。pip unstall: 也可以卸载通过python setup.py install安装的包
set mirror in mainland China¶
在win10下设置,参考Python pip 国内镜像大全及使用办法
在用户文件夹下新建pip文件夹,里面新建pip.ini文件
[global]
index-url=http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
注意编码格式为utf8无BOM。
pip install -i: temporary proxy
通过 conda 安装镜像在 .condarc 中设置, 如在内地可以用清华的镜像,而通过 pip 详见 pypi 镜像使用帮助,临时使用可以运行
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
pip install git+URL: install from github
For example, ESL-CN used the forked plugin, szcf-weiya/mkdocs-git-revision-date-plugin, to set the update time, then in the .travis.yml file,
pip install git+https://github.com/szcf-weiya/mkdocs-git-revision-date-plugin.git
‘Uninstalling a distutils installed project’ error¶
pip install --ignore-installed ${PACKAGE_NAME}
refer to ‘Uninstalling a distutils installed project’ error when installing blockstack #504
pip cache purge: remove cache
just found there is a cache folder, ~/.cache/pip, which occupied ~2G. From Removing pip’s cache? - Stack Overflow, got to know that pip itself can manage the cache, such as
$ pip cache purge
But pip cache seems not work in older version, such as pip 19.3.1.
sys¶
the first argument in sys.path.insert()¶
But for
sys.pathspecifically, element 0 is the path containing the script, and so using index 1 causes Python to search that path first and then the inserted path, versus the other way around when inserted at index 0.
The reason is that sys.path returns a list, while .insert is the method for a list, which insert object before the given index. Thus, if the first argument is 0, then the inserted path would be firstly searched, otherwise, it would be inserted after the first path, the current folder.
refer to First argument of sys.path.insert in python
key in sorted¶
As said in Key Functions – Sorting HOW TO, the key function is to specify a function to be called on each list element prior to making comparisons.
sorted("This is a test string from Andrew".split(), key=str.lower)
and met such technique in 4ment/marginal-experiments
unittest and coverage¶
-
candidate packages
-
the schematic of unittest framework in python: Running unittest with typical test directory structure
 coveralls-python
coveralls-pythonrun locally¶
- write unittest scripts in folder
test - install coveralls-python:
conda install coveralls - obtain the COVERALLS_REPO_TOKEN from coveralls
- run the script file
#!/bin/bash
cd test/
coverage run test_script.py
mv .coverage ..
cd ..
COVERALLS_REPO_TOKEN=XXXXXXXXXXXXXXXXXXXXXXX coveralls
combine with julia in Actions¶
combine the coverage from julia by merging the resulted json file, which need coveralls-lcov to convert LCOV to JSON.
refer to:
Misc¶
- 人工鱼群算法-python实现
- 请问phantom-proxy如何设置代理ip
- Python编码介绍——encode和decode
- 爬虫必备——requests
- Python使用代理抓取网站图片(多线程)
- python中threading模块详解(一)
- python 爬虫获取XiciDaili代理IP
- 使用SQLite
- python 使用sqlite3
- 用Python进行SQLite数据库操作
- Python调用MongoDB使用心得
- python urllib2详解及实例
- Python爬虫入门实战七:使用Selenium–以QQ空间为例
- Python中将打印输出导向日志文件
- python 中文编码(一)
- Python爬虫利器二之Beautiful Soup的用法
- 正则表达式之捕获组/非捕获组介绍
- Selenium using Python - Geckodriver executable needs to be in PATH